


Big Data is in the vogue. As a business leader, technology enthusiast, or aspiring technologist you need to be aware of the different database technologies what they can accomplish and how they align with your business needs. This article is by no means an exhaustive look at databases but rather a 30,000 foot flyover to help you familiarize yourself with an ever-expanding solution set. This was originally going to be called 5 database technologies in 5 minutes but the article started to get really large and I decided to split the article up.
Database Type #1: Relational
This database type should be familiar to you unless you have hidden under a rock the last 30 years. Say relational DB (database) and most people think Structured (not sequential :-) thanks Andre) Query Language (SQL). A relational DB consists of a set of rows and columns that comprise a table. A value within a table can be considered the primary key.
For example, you could have a products table and within this table your productID could be considered the primary key for that table. A visual example of this is below.
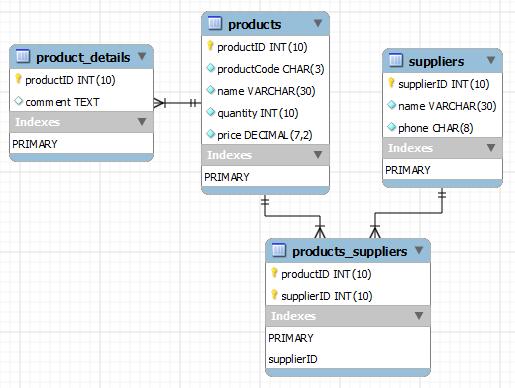
You can see that each Primary key has a Gold Key next to it. You can see that the tables are linking to other tables via their primary keys. You can see there are multiple values under the table and they are defined by data type. For example, quantity under the products table is set as an INT (integer) data type and has a maximum character limit of 10 characters.
Once you have the data into your database you then can mine the data using queries. A very simple query is below:
USE demodb
SELECT products.quantity from products
WHERE products.quantity > 0
Here I am telling the database query engine to select product quantities from the products table if those quantities are greater then 0. This is a VERY basic query and the sky is the limit when mining data from queries.
Database Type #2: Column-Oriented
Everything is chugging along great until one day you get data that is not so orderly and clean. Maybe it's a series of twitter posts, or unsorted transactions from multiple business units. This data is called semi-structured or non-structured data and it doesn't play nice with Relational databases. When dealing with non-structured data you need the ability to sort through the data to find the connections. It is here that we turn to column-oriented databases, specifically HBase.
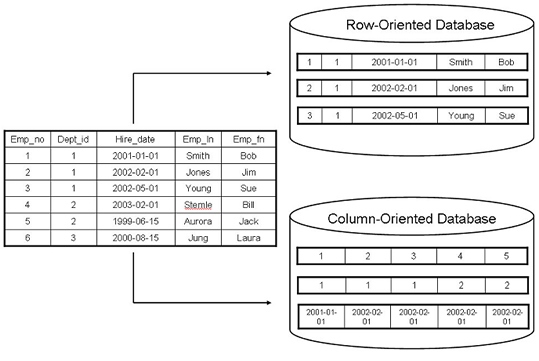 You can see the difference between the traditional row oriented database and the column oriented database.
You can see the difference between the traditional row oriented database and the column oriented database.
What is HBase?
HBase is an open source, non-relational, distributed database that is written in Java. At least, that is the definition according to Wikipedia. What does that mean? Let's break this out into laments terms.
Open Source- This means that the source code (pre-compiled code) is freely available for HBase. You could pickup the source code for HBase and develop your own version of a HBase executable.
Non-Relational- Remember the Primary key in the previous relational database example?
Well, as we can see productID is a primary key and has a parent-child relationship with the values under its table. In HBase a key value store is used in lieu of a schema which allows for unstructured data (however, HBase is not a key-value database)
Distributed Database- Distributed Databases are databases that are distributed. Pretty easy right? I could use many words to describe this to you but the image below seems to handle a distributed description quite well.

As you can see above utilizing RAID the database is distributed across multiple disks this allows for quicker data Read/Write/XFR as well as provides for redundancy. When you start to get into Big Data scenarios the ability to distribute data across a large quantity of commodity machines (low-cost data racks), is of key importance.
Once you have data in a column oriented database you need to analyze the data. One technology Hadoop, utilizes the distributed structure to store massive amounts of data that then are run through a MapReduce engine.
MapReduce:
In simple terms Map reduce maps in the unstructured data and sorts the data based on the Mapping parameters. Then the data is reduced in sets that can then be used to show trends in the data. An example would be to have the MapReduce function search through a series of twitter posts or emails looking for a few key words. The Map feature would map each occurrence of the word and the reduce feature would then create sets based on occurrence. With this information you could benchmark the response to advertisements and customer satisfaction in a Twitter feed by measuring the occurrence of key words.

Conclusion
This was orginaly going to be 5 databases but I simply didn't have the time. In the next installment I will be discussing 3 more database technologies. These will be:
- Graphing Databases
- Key- Value Database
- Document Database
I focused on two of the more common database technologies today and I look forward to your feedback and additional insight. Be sure to share this with your friends and subscribe to my blog.





